流式计算
为什么会出现流式计算?
在现实的业务中,会有需要统计计算的需求,一部分的日志需要计算统计信息。这时候会有两个思路。
一是当需求来的时候系统实时的计算一遍给出结果。
二是当日志信息收集上来的时候就进行一遍计算,把结果保存好。这时候需求过来的时候直接取结果就好了。
这两个方法分别是批量计算和流式计算。
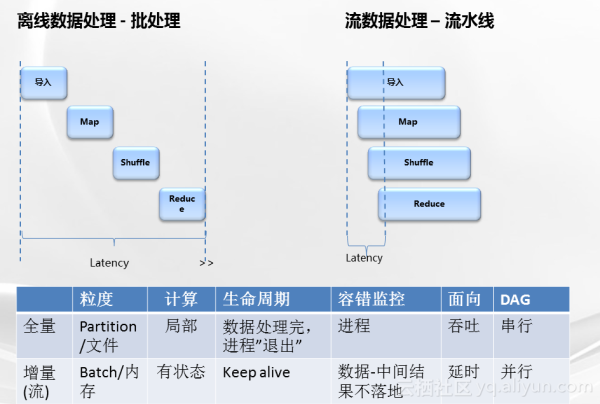
批量计算是一种用户主动发起,高时延(相对流式计算)的计算。他需要加载数据再开始计算流程。在使用一个数据流做输入的情况下他有batch的概念。需要等到数据量满足一个batch的大小后开始计算。
而流式计算更强调数据流的概念。数据到达处理和向后传递是不间断的。
总感觉,流式计算像是batch粒度为一个信息大小的批量计算。而且Spark streaming就是采用小批量(batch)的方式来实现流式计算。
现在的流式计算框架之间有什么差别
现在的流计算框架有 Twitter 的 Storm 和 Heron 还有 spark, finlk。
Storm
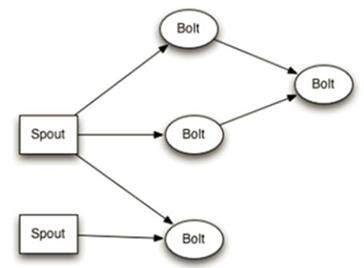
Storm 使用有向图的方式定义计算流程。称之为 Topology。其中 Tuple 是 Storm 的主要数据结构。
Spout 是有向图的数据源。它定义了数据的来源和去向,从来源接受数据发送给需要的节点。
Bolts 是有向图中的逻辑处理单元。从 Spout 中接受数据并处理。处理后的数据根据需要指向下一个节点或者储存。
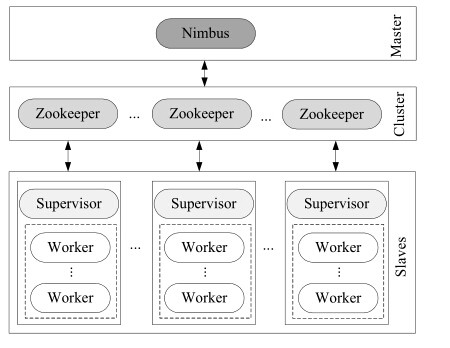
当定义好 Topology 便可提交到集群运行。Storm 集群主要由 Master node, Worker node 和 Coordinate node 构成。
Master node 上的 Nimbus 负责将应用代码分发给 Worker 节点 , 指派任务,并监控任务的执行。
Worker node 上的 Supervisor 负责监听从 Master node 分配来的任务,启动工作进程来运行相应的任务。
Coordinate node运行着 Zookeeper, 负责 Nimbus 和 Supervisor之间的通信。
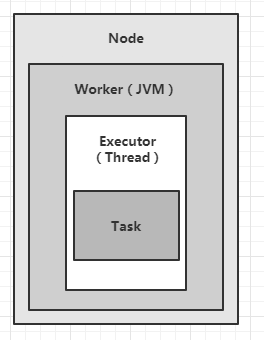
Worker (JVM虚拟机) 节点中每个 workers 是服务器上相互独立运行的JVM进程。 每一个node可以配置运行一个或者多个worker。一个topology会分配到一个或者多个worker上运行。
Executor(线程):是指一个worker的JVM进程中运行的Java线程。多个task可以指派给同一个executor来执行。除非是明确指定,Storm默认会给每一个executor分配一个task。
Task(bolt/spout实例):task是spout和bolt的实例,nextTuple() 和 execute() 方法会被 executors 线程调用执行。
Heron
随着 Twitter 的数据越来越多,单个 storm 集群规模也越来越大。storm 原有的架构不可避免的碰到了之前没有过的问题。包括:每分钟数十亿的事件;大规模处理具有次秒级延迟和可预见的行为;在故障情况下,具有很高的数据准确性;具有很好的弹性,可以应对临时流量峰值和管道阻塞;易于调试;易于在共享基础设施中部署。
Twitter 开始尝试对 strom做了一些改进,主要针对拓展性和稳定性。成果包括:使得Storm单集群可以容纳之前5倍的机器。但如果要继续改进,需要更改底层的设计和实现,代价很高,不亚于重新设计实现一个实时计算框架。
在这个需求指引下,第二代的流式计算引擎 Heron 便诞生了。
Heron 的设计目标包括
资源隔离 – 实时计算任务中的每一个节点和计算单元,应该确保能够使用且只使用它们分配的那些资源。这使得Heron在共享的基础设施上也保证资源分配以及资源隔离。
兼容性 – Heron与Apache Storm的API和数据模型是完全兼容的,降低在两个系统的迁移成本。
场景保证–Heron支持at-most-once,at-least-once,exactly-once等场景。并且在各种语义下,也可以通过不同的配置实现不同的取舍,如在exactly-once的场景下,可以通过配置选择低开销但恢复时间长、高开销但恢复时间短以及混合模式。
性能 – 许多Heron的设计选择使得Heron获得了比Storm更高的吞吐量和更低的延迟,同时还提供了增强的可配置性来微调可能的延迟/吞吐量的折中。
效率 – Heron的构建目标是以最小的资源使用量达到上述所有目标。
提供新的功能,如反压机制 – 在Heron这类分布式系统中,不能保证所有的系统组件以相同的速度执行。Heron有内置的反压机制来确保拓扑在组件缓慢的情况下可以自适应。
heron改进了一些strom框架下容易 形成系统瓶颈的地方。比如Storm的很多逻辑上相互独立的单元在实际实现中会共享资源。同时,这些资源在实践中发现是很容易成为瓶颈的。这一方面会影响系统的scalability和performance predictability,另外一方面,也很调试和进行异常处理。比如说,一个storm最小运行单元task出错的时候,可能会导致与之没有任何逻辑相关的其他task一起退出(因为系统实现的原因。)
总而言之。heron相比storm 在底层RPC, worker之间的模块做了变更。带来性能上的提升则是副产品(至少官方是这么说的)